NLP on Twitter Corpus
April 2022
1871 Words, 11 Minutes
Problem Statement
- According to research, roughly 80% of data is unstructured text data, therefore text analytics are essential for analysing the richness of data.
- Until recently, categorising text by hand and eyeballing it was the only method to undertake text analytics, which is time-consuming and inefficient.
- Additionally, this is not a practical approach for managing millions of papers, like the data from Twitter.
- Twiter corpus can be used to find trends related to a specific keyword, measure brand sentiment or gather feedback about new products and services.
Importing Libraries
- We start the project by importing libraries
- pandas: Used for data manipulation and analysis.
- numpy: Used for adding support for multi-dimensional arrays and matrices.
- nltk: Is a suite of libraries for statistical NLP for English language.
- tweepy:Python library for accessing the Twitter API
- re: Checks if a particular string matches a given regular expression
import pandas as pd
import numpy as np
import nltk
import re
import string
import tweepy
import os
from tweepy import OAuthHandler
import requests
from tqdm import tqdm
from bs4 import BeautifulSoup as bs
from urllib.parse import urljoin, urlparse
from requests_oauthlib import OAuth1
Twitter Authentication Keys
- We will pass the consumer key , cunsumer secret key , access token and access secret token linked with our account for authentication.
- Then using tweepy library the twitter corpus will be extrated
consumer_key = '0kpuv5mkHLpyCfWwhFwByZZ2g'
consumer_secret = 'nP4glPRfY05FsJ0RJSj44ZE3RIISvbaqytbfZ4LwnIrc4jLut0'
access_token = '1117402284730642432-m9hPPjsCOv62Uxl715MWzder76qOfA'
access_secret = '1f6VP99xM0fGhT8QSD2Fu1eLZwxwT9SAqFqFCsFvd1hpt'
auth = OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_secret)
api = tweepy.API(auth)
userID = "@CopywriterMaven"
tweets = api.user_timeline(screen_name=userID, count=300,include_rts = False)
print("Number of Tweets Extracted: {}.\n".format(len(tweets)))
Format the data in form of a datafram
data = pd.DataFrame(data=[[len(tweet.text), tweet.text, tweet.created_at, tweet.user.screen_name] for tweet in tweets], columns = ['Tweet_Length', 'Tweet_Text', 'Tweet_Date', 'UserName'])
data.head(100)
The output of this is:
Tweet_Length Tweet_Text Tweet_Date UserName
0 59 My answer to @MuckRack Daily's trivia question... 2022-02-14 18:23:10+00:00 CopywriterMaven
1 70 My answer to @MuckRack Daily's trivia question... 2022-02-11 19:47:15+00:00 CopywriterMaven
2 90 My answer to @MuckRack Daily's trivia question... 2022-02-07 18:10:35+00:00 CopywriterMaven
3 62 My answer to @MuckRack Daily's trivia question... 2022-02-03 18:16:52+00:00 CopywriterMaven
4 63 My answer to @MuckRack Daily's trivia question... 2022-01-24 18:17:27+00:00 CopywriterMaven
... ... ... ... ...
95 80 My answer to @MuckRack Daily's trivia question... 2020-12-29 18:04:33+00:00 CopywriterMaven
96 124 Turning Times Square Rocking Eve into the ulti... 2020-12-27 13:39:32+00:00 CopywriterMaven
97 84 My answer to @MuckRack Daily's trivia question... 2020-12-25 18:50:13+00:00 CopywriterMaven
98 34 @alfranken https://t.co/wauy9xnHaP 2020-12-25 17:16:32+00:00 CopywriterMaven
99 73 @CleverTitleTK I had to look up 'waxelene' ...... 2020-12-25 16:47:04+00:00 CopywriterMaven
100 rows × 4 columns
Preprocessing of Tweets
Since the tweets are a form of unstructured data we need to preprocess it so that it is free of all the irrelavant data such as spaces , punctuations , urls etc. We will perform the following
- Removal of extra spaces
- Tokenization
- Stop word removal
- Stemming
- Lemmatization
Removal of Urls
import re
urls= []
for i in data.Tweet_Text:
urls.append(re.findall(r'\b(?:http.*)',i))
urls
remove_urls = []
for i in data.Tweet_Text:
remove_urls.append(re.sub(r'\b(?:http.*)','',i))
remove_urls
Converting characters to lower case
data.Tweet_Text = data.Tweet_Text.apply(lambda x: x.lower())
The output is
Tweet_Length Tweet_Text Tweet_Date UserName
0 59 my answer to @muckrack daily's trivia question... 2022-02-14 18:23:10+00:00 CopywriterMaven
1 70 my answer to @muckrack daily's trivia question... 2022-02-11 19:47:15+00:00 CopywriterMaven
2 90 my answer to @muckrack daily's trivia question... 2022-02-07 18:10:35+00:00 CopywriterMaven
3 62 my answer to @muckrack daily's trivia question... 2022-02-03 18:16:52+00:00 CopywriterMaven
4 63 my answer to @muckrack daily's trivia question... 2022-01-24 18:17:27+00:00 CopywriterMaven
### Removal of special characters
data.Tweet_Text = data.Tweet_Text.apply(lambda x : re.sub("’" , "" , x))
print(string.punctuation)
special = set(string.punctuation)
data.Tweet_Text=data.Tweet_Text.apply(lambda x: ''.join(ch for ch in x if ch not in special))
Removal of extra spaces
data.Tweet_Text=data.Tweet_Text.apply(lambda x: x.strip())
data.Tweet_Text = data.Tweet_Text.apply(lambda x: re.sub(" +", " ", x))
Tokenization
- Is a way to break down a sentence into smaller units called tokens separated by comma
all_tweets_text=set()
for tweet in data.Tweet_Text:
for word in tweet.split():
if word not in all_tweets_text:
all_tweets_text.add(word)
Filtering stop words
words = list(all_tweets_text)
sorted_list = sorted(words)
nltk.download("stopwords")
from nltk.corpus import stopwords
stop_words = set(stopwords.words("english"))
stop_words
filtered_list = []
for word in sorted_list:
if word not in stop_words:
filtered_list.append(word)
Stemming
- In linguistic morphology, stemming is the process of reducing inflected words to their word stem, base or root form—generally a written word form
from nltk.stem import PorterStemmer
stem_words = []
ps = PorterStemmer()
for i in filtered_list:
stem_words.append(ps.stem(i))
Lemmatization
- Is a text normalization technique used in Natural Language Processing (NLP), that switches any kind of a word to its base root mode.
from nltk.stem import WordNetLemmatizer
lem_words = []
lem = WordNetLemmatizer()
for i in filtered_list:
lem_words.append(lem.lemmatize(i))
lem_words
POS Tagging
- Is a process of converting a sentence to forms – list of words, list of tuples (where each tuple is having a form (word, tag)). The tag in case of is a part-of-speech tag, and signifies whether the word is a noun, adjective, verb, and so on.
stem_pos = nltk.pos_tag(stem_words)
lem_pos = nltk.pos_tag(lem_words)
stem_pos
lem_pos
Finding top 10 most frequent words
freq = nltk.FreqDist(lem_words)
top10 = freq.most_common(10)
top10
This gives us the output:
[('family', 2),
('joke', 2),
('movie', 2),
('reason', 2),
('right', 2),
('thing', 2),
('time', 2),
('today', 2),
('word', 2),
('year', 2)]
Word Cloud Generation
- Word Cloud is a data visualization technique used for representing text data in which the size of each word indicates its frequency or importance.
- Significant textual data points can be highlighted using a word cloud.
- Word clouds are widely used for analyzing data from social network websites.
! pip install wordcloud
from wordcloud import WordCloud
import matplotlib.pyplot as plt
wordcloud = WordCloud(background_color = 'black').generate(str(top10))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
The output is
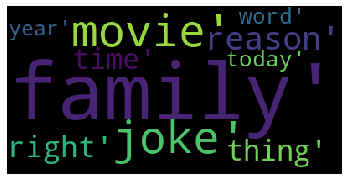
N-Gram Model
- An N-gram language model predicts the probability of a given N-gram within any sequence of words in the language.
- A good N-gram model can predict the next word in the sentence i.e the value of p(w|h)
- Example of N-gram such as unigram (“This”, “article”, “is”, “on”, “NLP”) or bi-gram (‘This article’, ‘article is’, ‘is on’,’on NLP’).
Uni-Gram
#Uni-gram
from nltk.util import ngrams
n = 1
unigrams = ngrams(lem_words, n)
for item in unigrams:
print(item)
Bi-Gram
#Bi-gram
from nltk.util import ngrams
n = 2
unigrams = ngrams(lem_words, n)
for item in unigrams:
print(item)
Tri-Gram
#Tri-gram
from nltk.util import ngrams
n = 3
unigrams = ngrams(lem_words, n)
for item in unigrams:
print(item)